Adventures with nom
Estimated reading time: .
Some things I learned while using the nom library on a parser project.
My primary side project at the time of this writing is a parser for the COSMOS message definition language. I’m writing it mostly to learn how to make a useful parser, and to see what I can do from there. I have hopes that it might be useful at work some day, but for now it’s purely educational.
I’m using the excellent nom crate to power the parser. I do not, at present, have a lexer or tokenizer – I take a run of text and immediately begin attempting to identify patterns in the text and create data structures.
In case you’re curious, I do have most of a finite-state-machine diagram written for the bulk of the grammar:
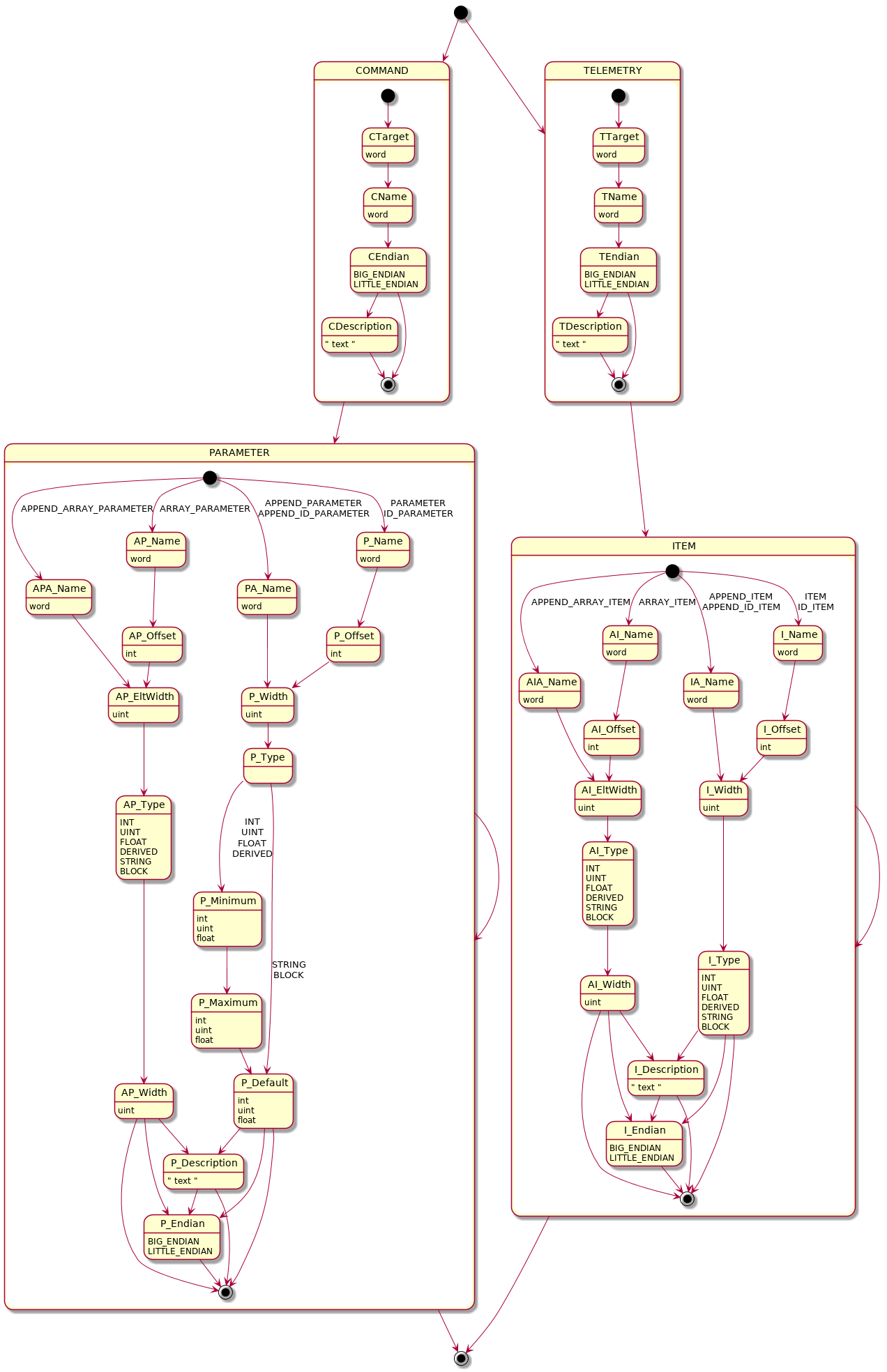
I say most, because there is a long tail of less common modifier elements that can affect elements, but these are the four main elements that comprise 80% of the source text. Adding them to the diagram in a useful manner made it a visual nightmare, so I elided them.
Parsing
I opted to work without a lexer stage that converts the source text into a stream of token items that the parser can then consume. I may refactor to use a pipeline like this in the future, though I’ll probably wait for generators to stabilize rather than use an iterator and have to shoehorn in Result signals.
The parser is a tree of nom parsers, using macros from the library and my own functions to transform text segments into data items. I rapidly found that nom is a highly composable library – the parse tree is composed of parser routines that all return the same general type that carries error information, a parsed value, and the remaining unparsed text. This type is a carrier that can be passed from parser to parser, each of which knows how to propagate failures upward or emit parsed values to the user and continue operating on the unparsed source.
Now that nom version 4 uses the standard library’s Result type as its carrier, the ? operator can be used as a quick fail-upward mechanism, and other patterns in the ecosystem can work on the Result without requiring adaptation. I use this with the tap crate in order to provide transparent logging functionality.
A consistent type wrapper that can traverse the entire parse tree, yet change the parsed value it carries as the work occurs, is very powerful.
Example Parsers
Here are some snippets of my work that show off nom’s power in compositional functions and macros:
use nom::types::CompleteStr;
type ParseResult<'a, T, E = u32> = nom::IResult<CompleteStr<'a>, T, E>;This prelude pulls in a newtype wrapper over &str that signals to the nom parsers that the source is fully loaded, and no more will be fetched. If the parsers run out of text to make a decision, then the source is invalid.
I then define a partially-constructed carrier type that takes nom’s generic carrier, IResult, and defines it to always have a CompleteStr as the source type. The parse-value and error types are left for each call site.
/// Lexes a single word (denoted by whitespace, non-whitespace, whitespace)
fn word(text: CompleteStr) -> ParseResult<CompleteStr> {
ws!(text, take_till!(char::is_whitespace))
}
/// Lexes a hex number
fn hnum(text: CompleteStr) -> ParseResult<u64> {
preceded!(text, ws!(tag!("0x")), word).and_then(|(rem, num)| {
u64::from_str_radix(&num, 16)
.map(|x| (rem, x))
.map_err(|_| nom_error!(num, 'x' as u32))
})
}The first function is just a wrapper over a nom macro to strip leading whitespace, then advance the cursor through non-whitespace text, and strip trailing whitespace. It returns a view into the source text representing one logical word.
The second function uses nom macros to strip leading whitespace and require that the trimmed text begins with 0x. If ws!(tag!("0x")) fails, then the preceded! macro fails, and returns an error. If the 0x tag is found, then preceded! invokes the word function. Since word follows the carrier input and output patterns that nom expects, it can accept a foreign function about which it knows nothing. The result of word is then the result of preceded!. I then use the standard library’s Result behavior to further manipulate the text returned from word if it succeeded, and short-circuit to an error if it did not.
Line 9 tries to parse the found word (num) using the standard library’s knowledge of what base-16 text looks like. If it succeeds, it returns the number directly. This does not fit our carrier pattern, so line 10 maps it from Result<u64, _>::Ok(u64) to ParseResult<u64>::Ok((CompleteStr, u64)) on success.
Line 11 replaces the standard library’s error, which is not in the nom carrier pattern, with a nom error that knows about the text that failed.
Let’s show one more:
/// Lexes any unsigned integer, including name words and hex digits.
fn unum(text: CompleteStr) -> ParseResult<u64> {
use std::{u8, u16, u32, u64};
word(text).and_then(|(rem, num)| num.parse::<u64>()
.or_else(|_| {
alt!(num,
tag!("MIN_UINT8") => { |_| u64::from(u8::min_value()) } |
tag!("MAX_UINT8") => { |_| u64::from(u8::max_value()) } |
// repeat through u64
// then try the hex parser
hnum
).map(|(_, u)| u)
})
.map(|u| (rem, u))
.map_err(|_| nom_error!(num, 'u' as u32))
)
}This is a much more complex parser; let me break it down.
Line 4 finds a logical word in the text.
.and_thenis invoked only if it succeeded, so a failure exits the function immediately. Note that the closing parenthesis of.and_thenis on line 15; everything inside depends onwordsucceeding!Line 4 then attempts to use the standard library’s string-to-number parser.
If
num.parsefails, then the.or_elsefrom lines 5 to 11 is invoked. This drops the standard library’s error, and tries to match a series of named keywords that correspond to numbers. Thealt!combinator takes innum, the success output ofword, and tests if it is the listed strings. If one matches, then the right side of=>fires, and a u64 is returned!This also attempts the hexadecimal parser on line 11, since hex numbers are valid unsigned integers.
alt!is a little magic – the transform after thetag!calls is actually altering only thevalinOk((rem, val))– and this doesn’t need to be done on the output value ofhnum, which is already au64.Line 12 receives the
ParseResult<CompleteStr, u64, E>fromalt!and drops the unparsed output of success – we statically know it will be an empty string, becausewordmade sure that thenumvalue had no extraneous text – and returns only the number. This is necessary becausenum.parsereturns a bareOk(u64)on success, and therefore the closure inside.or_elsemust also returnOk(u64)or else the types don’t match and the interiorResultcarrier fails!Line 13 terminates the
.or_else()call, bringing us back up to the.and_thenclosure.The
.and_thenclosure must return aParseResultcarrier, which is a totally different type than the result of the standard library parser! The output ofnum.parse().or_else()isResult<u64, _>but we need aResult<(CompleteStr, u64), NomError>!Thus, line 14 changes the success type from
u64to(CompleteStr, u64)by adding in the remainder of the text that from whenworddid its work, and line 15 throws away the standard-library error type and replaces it with anomerror type specific tounum.
Newtype Wrappers
nom uses a common Rust pattern of wrapping a semantically-meaningless type in a semantically-meaningful type that only exists at compile time. In this case, CompleteStr is just pub struct CompleteStr<'a>(pub &'a str);. The binary representation is exactly the same as &'a str, but the compiler sees &str and CompleteStr as two completely different types and thus allows nom to make different code paths for them – specificall, CompleteStr means that the source buffer is always fully present and thus assumptions can be made about processing it that cannot be made for a bare &str that might have more data arrive later.
This is a nice pattern, and was easy to adopt by just changing all my functions to take a text: CompleteStr instead of text: &str and changing ParseResult to use CompleteStr instead of &str as the source type.
EXCEPT!
Lifetimes and References
During my process of porting my project to use CompleteStr instead of str, I swiftly ran into fun problems.
First: a CompleteStr isn’t an &str. Therefore, methods on &str don’t apply to a CompleteStr, so all my text.trim() and similar calls suddenly fail.
The easiest solution is to go replace them with CompleteStr(text.0.trim()) but this is inelegant and uncomfortable.
It works, though, because trim() and associated methods return an &'self str with the same lifetime 'self as the &str that entered into it. Thus, for any CompleteStr<'a>(&'a str) whose inner member is extracted and trimmed, a different &'a str comes out of trim() and can be rewrapped in a CompleteStr<'a>.
This is sound, but ugly.
Deref Bug
Enter nom PR #715.
This PR was a welcome addition, which implemented Deref on CompleteStr to get at the inner &str without explicit destructuring and restructuring.
Here’s the code:
pub struct CompleteStr<'a>(pub &'a str);
impl<'a> Deref for CompleteStr<'a> {
type Target = str;
fn deref(&self) -> &str {
self.0
}
}It took me a solid week to see the problem here. Do you?
Rust allows us to elide lifetimes and dereferences in a lot of places. Let me rewrite this with all of the lifetimes and dereferences in place.
impl<'a> Deref for CompleteStr<'a> {
type Target = str;
fn deref<'self>(&'self self) -> &'self str {
&*self.0
}
}The dereference function borrows a CompleteStr and returns an interior borrow. The lifetime of the borrow is 'self, the scope in which the CompleteStr is valid; it is not 'a, the scope in which the referent str is valid.
*self.0 is a str object, and it is immediately reborrowed for 'self. The lifetime information 'a is lost, and cannot be recovered.
Deref Solution
The solution required me to really think about how Rust tracks borrows and lifetimes, and what references are in the program representation.
str and [T] are hard types with which to work, because they are what Rust calls !Sized – they can be any width, and thus cannot be held directly. The allocator manages their memory, and your code must refer to them indirectly, with a pointer of some kind. The compiler helpfully makes it so that references to str or slice are not just the address of the first byte, but also the length. Mechanically, &str is equivalent to (*const u8, usize).
Because str is an indirect type, it’s important to note that nom’s decision on how to construct CompleteStr (the same is true for CompleteByteSlice and [u8]; I just don’t want to type out two types for the same concept) affects how it is used.
nom could have chosen to make the wrapper be over str directly:
pub struct CompleteStr(pub str);and require that it always be accessed behind a &CompleteStr reference. I have not tried this at time of writing, in part because I thought of it only a few paragraphs ago, and so I might experiment with that.
But nom made CompleteStr wrap a reference to str instead. This makes the CompleteStr type a tuple of pointer and length, and we are able to treat its two words as a handle to UTF-8 text. (Incidentally, this means that completeness in the nom sense is a property of the reference handle, not the referent data, which I think may have interesting consequences.)
The borrow of a CompleteStr is not an &str. It is a one-word pointer to two words, and those two words merely happen to be a pointer to data.
Immutable references &T are copyable. Mutable references &mut T are not copyable, and have move semantics, but we are dealing only with immutable for this post and so I don’t need to go into that very much.
Furthermore, CompleteStr implements Copy. This means that whenever a CompleteStr is given to a new scope, the new scope receives a copy of two words and this copy can be, and will be, lost at the end of the scope.
When a new scope is created that has access to a CompleteStr, it is given two words that contain a pointer and a length. When that CompleteStr is borrowed, Rust points to those two words; it does not copy them.
This is the consequence of designing CompleteStr as a wrapper around a text reference and then implementing Deref in the manner I described above: the end result of Deref is a reference that has the current scope lifetime, even though the referent outlives it. Had CompleteStr been a wrapper around str instead of &str, then the Deref implementation would have been correct as written and the lifetime hairiness probably would not have come up, because CompleteStr would have the same lifetime as the str it wraps, and would NOT have been a handle type.
Once I realized what was being emitted from the dereference function, and what the Deref trait required of its implementors, the solution was relatively straightforward. Deref returns a reference to the interior of the handle, and this reference has the handle’s lifetime.
impl<'a> Deref for CompleteStr<'a> {
type Target = &'a str;
fn deref<'self>(&'self self) -> &'self &'a str {
&self.0
}
}Ultimately, we don’t need to care whether we have a reference to an &str or a copy of it. What matters is that the lifetime information of the source data is preserved. After dereferencing a CompleteStr, we have the address of a pointer to str. This also means that we can reconstruct a CompleteStr<'a> from the reference obtained by this method: references are copyable, so dereference &'_ &'a str to get a copy of &'a str and wrap that in CompleteStr<'a> and everything is handled.
In my PR #725 to fix this, I also added a From implementation for building a new CompleteStr from a reference to &str:
impl<'a, 'b> From<&'b &'a str> CompleteStr<'a> {
fn from(src: &'b &'a str) -> CompleteStr<'a> {
CompleteStr(*src)
}
}and the end result is that it’s now very easy to do str operations on CompleteStr: calling completestr.str_method().into() will perform the str operation and then immediately rewrap the emitted &str, and this pattern is now strewn throughout my project to great success.
Conclusion
These are a few of my experiences building a parser; I’ll update this post or write sequels as I move forward.
nom is a really cool tool for churning through source material. It’s not a substitute for a proper design, though, which I definitely didn’t have before starting! I may go back and split my parser into separate lexing and parsing phases, so I can do things like treat quoted strings as single elements, or carry source span information through the parser so I can have better error messages.
My main future concern is that nom is linear and eager. The linearity may cause some problems going forward – for instance, if I want to expand the parser input space to include comments, I will have to modify a lot of parsers to identify and discard comments at any point in the stream – and the eagerness means that any given function will either succeed entirely, or else fail, but if I want to accept a partial success and attempt recovery, I have a harder time.
I think my goal for a refactor would be to use nom to create a lexer that advances through a source stream and produces tokens, and use that lexer to power an Iterator or, when stabilized, a Generator so that I can have more fluent command of the token stream and the way it is processed.
Comments would definitely be easier to handle this way: have a filter call after the token Generator but before the structure parsers that just drops any comment tokens coming through.
I’m having a lot of fun on this project and it’s been a wild learning experience so I hope I’m able to release some code from it in the near future!